
Every AI engineering YouTube video says the same thing in a slightly different voice.

I watched dozens of them. RAG tutorials, agent framework walkthroughs, prompt engineering breakdowns. Different creators, different thumbnails, same content recycled through slightly different mouths. After three months I could describe what RAG was at a dinner party but couldn’t explain my own retrieval pipeline in formal terms during a technical screen. The videos gave me confidence without competence. I felt like I was learning. I wasn’t.
The problem wasn’t the content. The content was fine. The problem was that content is the wrong unit of learning.
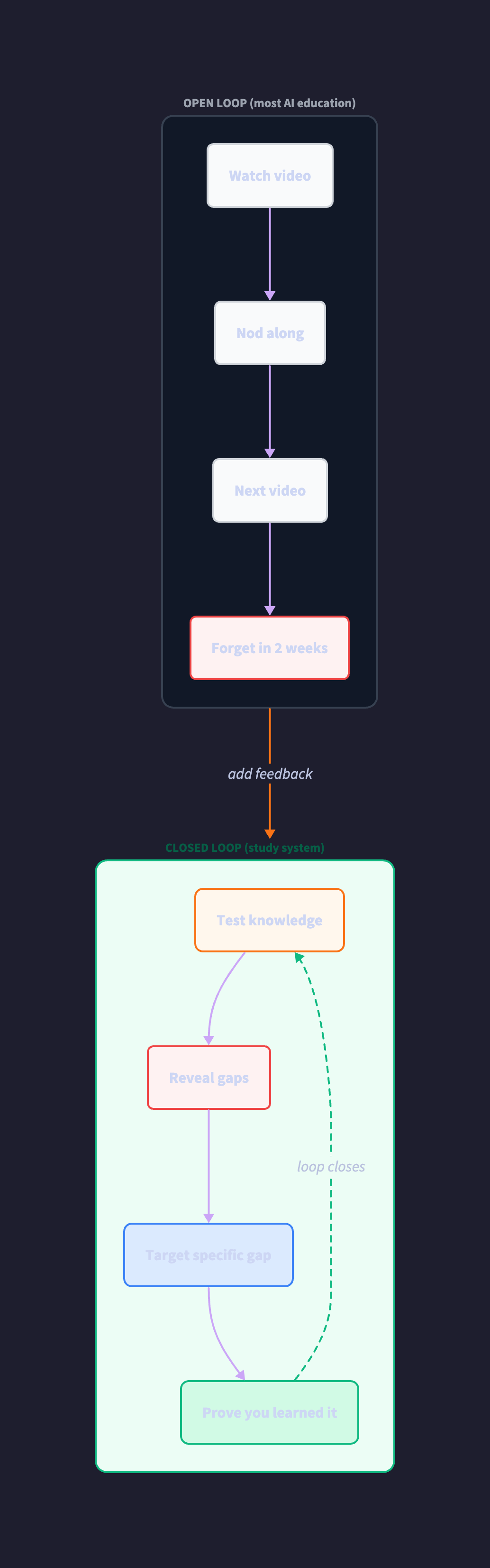
Here’s what I mean. A YouTube video is an open loop. Information goes in. Nothing comes back. No measurement. No correction. No proof you retained anything. You watch, you nod, you feel smart, you move to the next video. The creator gets a view. You get a dopamine hit. Nobody checks whether you can explain what you watched under pressure two weeks later. The entire AI education industry the courses, the tutorials, the threads, the bootcamps optimizes for content production. More videos. More modules. More “comprehensive” curricula. All of it open loop.
Learning doesn’t happen in open loops. Learning happens in closed loops where output feeds back into input, where measurement drives correction, where gaps revealed by testing become the targets for the next iteration. This isn’t a metaphor. It’s systems thinking applied to the one problem every engineer faces when preparing for a new role: how do you actually know what you know?
I have three AI platforms running in production. Dozens of agents, a thousand-plus tests, real users, real money. I’m not breaking into AI from scratch. I’m trying to learn the formal vocabulary for what I already built, so I can articulate it to people who expect textbook terms. But every learning resource assumed I was starting from zero. Week 1: What is a transformer. Week 2: Introduction to RAG. I’ve been running RAG in production for over a year. I don’t need an introduction. I need a system that knows what I’ve built and closes the gap between my working knowledge and the industry vocabulary.
So I went back to books. Chip Huyen’s AI Engineering. Designing Data-Intensive Applications. Architecture Patterns with Python. Classical material. And something clicked every chapter described something I already did. CQRS? I run separate databases for operational writes and analytical reads. Repository pattern? That’s my tool layer. Service layer? My endpoint calls one function that orchestrates everything. AI-as-Judge evaluation? I have twenty-two rubrics scoring agent output.
The classical material was always good enough. The books cover everything the YouTube videos cover, three layers deeper, with the formal vocabulary that matters in interviews. The problem was never content quality. The problem was that content no matter how good is still an open loop without a system around it.
So I built the system.
Not a reading list. A closed-loop learning system with state, feedback, and gates. The difference matters. A reading list is “here are 50 resources, good luck.” A system tracks where you are, tests what you know, identifies what you don’t, and routes you to the specific resource that closes the specific gap. The system corrects itself. The reading list just sits there.
The architecture is simple. Three components forming a reinforcing feedback loop:
The first component is the curriculum a spreadsheet mapping every formal concept to my own production code. A hundred and sixteen rows. Each row says “this resource teaches this concept, and YOUR code in this file implements this pattern.” Not generic examples. My actual architecture, annotated with formal vocabulary. “Your market tools module IS the repository pattern.” “Your webhook handler IS event-driven architecture.” “Your dual-database setup IS CQRS.”
The second component is the testing gate. Each topic gets scored: KNOWN, CLOSE, or GAP. KNOWN means you explain it cold, no notes. GAP means you can’t. CLOSE means right intuition, wrong terms you use the pattern daily but fumble the vocabulary under pressure. You don’t advance past a topic until the score moves. The gate is what makes this a system instead of a list. Without it, you’re just consuming content and hoping.
The third component is the feedback loop itself. Gaps revealed by testing drive the next study session. Not “what comes next in the curriculum.” What YOUR scores say you need. The system routes you to targeted resources based on measured deficiency, not linear progression. Study, test, reveal gaps, target gaps, test again. The loop closes.
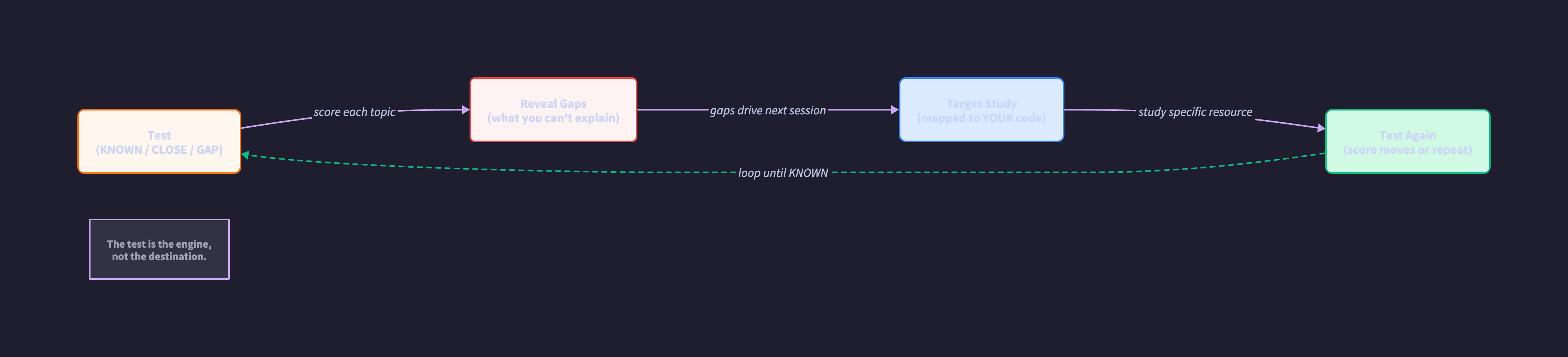
That reinforcing loop is the whole insight. Most engineers study like this: consume content → feel progress → move on. No measurement, no correction, no proof. The system flips it: test first → reveal gaps → target study → test again → confirm learning. The test isn’t at the end. The test is the engine.
CLOSE turned out to be where most of my knowledge lives. And I suspect it’s where most experienced engineers’ knowledge lives too. The gap between “I do this every day” and “I can articulate this in industry vocabulary” is small in effort but enormous in career impact. An interviewer doesn’t know you built a production RAG pipeline with hybrid search and reranking unless you can call it “advanced RAG with reciprocal rank fusion.” Otherwise they hear someone describing a search feature. The CLOSE category is the highest-ROI target in the entire system small effort, massive career unlock.
The anti-patterns made it into the curriculum too. The thousand-line prompt that tried to do everything? That’s the god object pattern, and I needed to name it to explain why I replaced it with six deterministic pipelines. The three parallel execution systems I consolidated into one? That taught me more about architecture than any chapter, because I lived the cost of the mistake before learning the formal description. My own failures became study material. A closed-loop system doesn’t hide from errors it feeds on them.
I turned the whole methodology into a meta-prompt. A prompt that generates personalized study systems for any technical domain. It interviews you twice before generating anything your background and projects first, then a vocabulary baseline where you explain key terms and get scored KNOWN, CLOSE, or GAP. Only then does it build the curriculum mapped to YOUR code, with testing gates, interview scripts, and custom notebooks that annotate your architecture with formal vocabulary.
The system works for domains I didn’t design it for. Data engineers get different baseline terms. DevOps people get different project mappings. The two-interview structure is domain-agnostic. The specificity comes from what you tell it. The system thinking stays the same: closed loop, feedback-driven, state-tracked, gap-targeted.
I showed the methodology to a few people. What landed wasn’t the AI tooling. It was the systems thinking. The realization that they’d been consuming content for months in an open loop watching, reading, nodding, forgetting and never building the feedback mechanism that turns consumption into competence. The system isn’t complicated. It’s three components and a loop. But it’s the difference between feeling like you’re learning and proving that you are.
The AI education industry will keep producing content. More courses, more tutorials, more creators recycling the same explanations with better production value. That’s fine. Content isn’t the enemy. Content without feedback is. The missing piece was never better videos or more comprehensive curricula. The missing piece was a system something that tracks state, tests knowledge, reveals gaps, and routes correction. Something that closes the loop.
Build the loop. The content was always there.
Github link below